Sitecore JSS @ Scale | DevOps
DevOps — IaC & ephemeral environments

Sitecore JSS @ Scale
3. DevOps — IaC & ephemeral environments
Intro
The advent of Sitecore JSS & it’s headless server-side rendering of node applications opens up a whole new world of cloud infrastructure and DevOps tools. The first thing any React developer will be thinking is which flavour of Kubernetes am I deploying my application too?
That is a big shift from Azure App Service — the current cloud deployment model for Sitecore. In the broader tech industry, containers and container orchestration platforms, specifically Kubernetes (and the many variants of), is the norm. With the steady breakup of Sitecore into dotnet core microservices, Kubernetes is very much the future of Sitecore too. And that is a good thing, it brings with it far more control, rolling updates, self-healing and greater resilience because the cluster IaaS can be distributed across datacentres or availability zones.
Most who have worked with Sitecore in Azure will be familiar with the ARM template you can use to spin up an instance in a few minutes.
 It even lives in the market place so you can spin up Sitecore with ease.
It even lives in the market place so you can spin up Sitecore with ease.
That is a good way to get started, but it doesn’t create production ready enterprise infra. It also doesn’t create anywhere for you to deploy your swanky new SPA front-end application to — there’s no Linux containers in there.
Organisationally, the decision had been made to solve some of the more intricate change planning and execution problems associated with infrastructure as code (IaC) using Hashicorps Terraform (terraform.io). This is great as it allows us to manage how changes to infra happen in yaml templates.
So, in true engineering fashion, we started to tear apart the ARM templates into modules that would allow us more granular deployments.
The challenges we faced were:
· How do we structure our templates so that we can deploy multi-region, single-instance for production vs single-region, multi-instance for dev?
· How do we deploy those configurations reliably from scratch and gain the benefits of ephemeral environments?
How we did it
Deployment of our Sitecore instances and related websites is currently broken down into three distinct stages.
Any suggestions on better names for these stages would be highly welcomed — we’ve agonised over many combinations and couldn’t agree on anything better!

On weekday nights we teardown and recreate our infrastructure to test our release scripts and to save money on our Azure Subscription for dev/test. When tearing down infrastructure in the evening, we only destroy some resources such as the SQL server and App Service Plans.
Because of this, the teardown includes a step to do a database backup and the backup is restored the following morning.
Given the App Service Plans are removed, the following morning we need to re-deploy all of the Sitecore instances and their respective websites so that they are present. This is a side effect of recreating the App Service and App Service Plans, which in turn resets our config.
Because of all of this, the easiest way to bring everything back up in the morning following a teardown is to trigger the deployments for everything in order. For example, we will trigger the Heavyweight deployment which will create all of the core infrastructure, then trigger the Lightweight deployments which will trigger creation of the sitecore instance, and then trigger the environment/site deployments which will then deploy the sites which point to the instances. This coordination is done through a collection of scripts which trigger re-deployments of Stages of Release Definitions in Azure DevOps.
Morning spin up
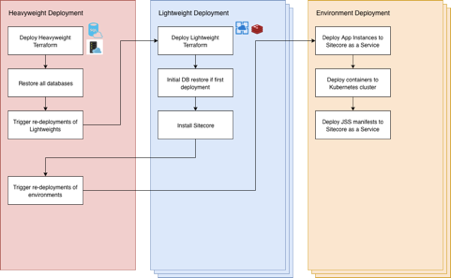
Heavyweight deployment
1. Create heavyweight infrastructure on Azure using Terraform
2. Run database restore which will restore all of the databases from the previous day
3. Trigger re-deployment of Lightweight instances (see Lightweight deployment) and wait for completion
4. Trigger re-deployment of environments/sites but don’t wait for completion
If creating the heavyweight infrastructure with Terraform fails or the database restore fails, the process will be cancelled and the Lightweight instance deployments won’t get triggered.
Lightweight deployment
- Create lightweight infrastructure on Azure using Terraform
- Create app services in app service plans created by Heavyweight
- Create Redis cache
- Create wildcard certificates ready for app instance CM/CD/Preview hostnames
- Run initial Sitecore Installation DB restore if no database is currently present. This will only affect new Sitecore Instances as existing ones will have their data backed up by the overnight backup and restored.
- Install Sitecore (at the moment this script doesn’t seem to be entirely idempotent, during execution a Sitecore instance goes down for a bit)
Environment deployment
- Deploy app code to sitecore instance
- Create DNS records for CM/CD/Preview
- Assign wildcard certificates created during Lightweight to these new hostnames
- Deploy containers to Kubernetes
- Deploy JSS manifests to Sitecore instance
This is done last as JSS changes may contain field renames, additions etc, which may require frontend code to be deployed first.
Evening tear down
Heavyweight
1. Trigger deployment of Lightweight teardowns
Lightweight instances have to be torn down first as you can’t delete an App Service Plan until the App Services have been deleted.
2. Backup all databases
This process doesn’t have any knowledge of Sitecore and just blindly backs up all databases in the SQL server.
3. Terraform destroy Heavyweight infrastructure
We only destroy App Service Plans and SQL server. Keyvault remains as it contains important secrets and doesn’t cost much.
Lightweight
1. Terraform destroy Lightweight infrastructure
We tear down the App Services and Redis Cache, ancillary resources such as certificates are left intact as there is no need to destroy them.
Kubernetes
You might be thinking, what lives in Kubernetes when Sitecore is currently full fat dotnet and runs in App Service?
Answer:
- Solr cloud (prep for multicloud)
- Sitecore publishing service
- Sitecore Identity
- Nix build agents
- Sonarcube
- ELK
- Grafana
- Prometheus
- BFF/app gateway
- A bunch of domain specific microservices
- And of course, our JSS React app
So that’s the hipster-devs checklist complete.
Solution Boundaries
Our system goals are quite simple: run Sitecore as a [single source of truth] content service across the enterprise, deliver content to multiple microservice applications and decouple the front-end deployments from the back end. This means we have effectively got 2 solutions:
1. Sitecore
2. Nationwide.co.uk
We have a separate pipeline for the JSS React App so it can be independently deployed. We are however, working with a CMS, where front-end changes might require template changes. We have tackled this problem in two totally dfferent ways to date— which warrants it’s own blog post.
The result
Perhaps overkill, but we have been able to spin up an entire instance of Sitecore for a PR merge branch. This enables us to ensure a merge passes all automation tests before code is finally merged back into master. It also means manual tests could be run. We actually have a grafana dashboard that enables us to see/monitor/destroy these instances if required.
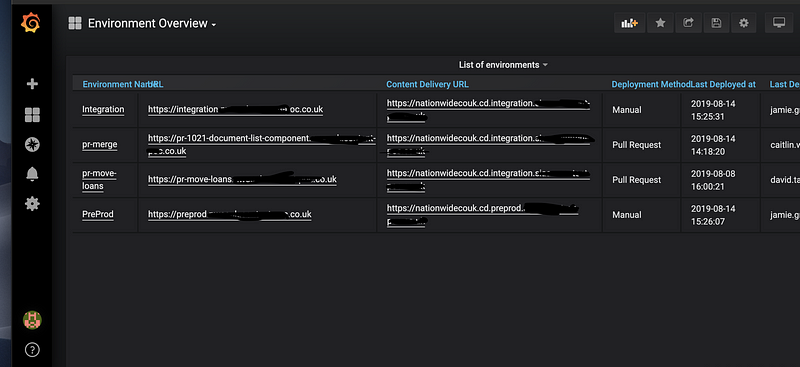
Whats next
We still have a lot to work through like blue/green slots for app services, maturing DevSecOps, increasing test automation and — being a financial services organisation — a long list of regulatory controls to comply with.
kudos to Jamie Greef f— who’s internal wiki I ripped off much of this content from :)
By Rich James on August 15, 2019.
Exported from Medium on January 28, 2020.