The Dario Amodei Hype Machine: Mythos, Fable, and the Smell of an IPO
There's an old saying in Silicon Valley: if you can't ship it, at least name it something terrifying. Anthropic, the safety-focused AI lab run by Dario Amodei, has elevated this principle to an art form.
Let's talk about the last six months of Claude releases, the benchmarks, the government drama, and whether any of this was ever really about the technology.
Act I: Mythos — The Model Nobody Got to Actually Use
It started in March 2026 with a leak. A configuration error exposed thousands of internal Anthropic documents, including draft marketing copy for a new model ominously named Claude Mythos. The copy described a system of near-apocalyptic capability — a model so powerful it could discover thousands of zero-day vulnerabilities across major operating systems. The internet duly lost its mind.
Spiceworks broke down what the hype actually obscured: the "thousands of zero-days" figure came not from Anthropic's peer-reviewed research but from its marketing page for Project Glasswing. When analysts dug into the 244-page technical System Card, that scary number was nowhere to be found. The actual methodology? Human contractors manually reviewed 198 vulnerability reports. Anthropic then extrapolated the 90% agreement rate across the model's entire raw output and called it confirmed critical flaws. That's not science. That's a press release wearing a lab coat.
The Firefox exploit that made the headlines? Mythos wasn't attacking a real Firefox installation. It was attacking a SpiderMonkey JavaScript shell inside a container, with the process sandbox and standard browser defences entirely stripped away. It's a bit like claiming your new car does 200mph — in neutral, being towed downhill.
Mythos Preview was real. It was capable. The SWE-bench Verified score of 93.9% was legitimately impressive. But it was gated, restricted, and shrouded in Pentagon-adjacent mystique. Most developers never touched it.
Act II: Fable — The "Mythos for the Rest of Us"
On June 9th, 2026, Anthropic launched Claude Fable 5 — described as "a Mythos-class model we've made safe for general use." The marketing was predictably spectacular. SWE-bench Pro scores! FrontierCode leadership! An 11-point lead! Stripe migrated a 50 million line codebase in a day!
Before we get into numbers, a word on benchmark integrity. SWE-bench Pro and Anthropic's internal evals have both faced serious questions about methodology — vendor scaffolding, self-reported scores, and in some cases outright contamination. They're not worthless, but they're not gospel either. The one benchmark that has consistently held up as a genuine, third-party, hard-to-game test of real agentic coding ability is DeepSWE — along with Terminal-Bench and SWE-Atlas-QnA as part of the Artificial Analysis Coding Agent Index.
So let's look at what the unimpeachable leaderboard actually shows:
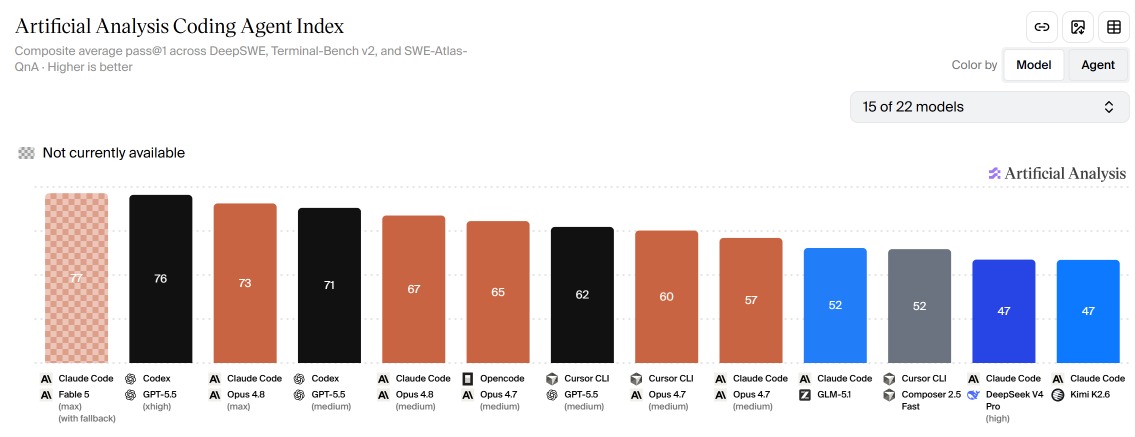 Source: Artificial Analysis Coding Agent Index — composite average pass@1 across DeepSWE, Terminal-Bench v2, and SWE-Atlas-QnA. Higher is better.
Source: Artificial Analysis Coding Agent Index — composite average pass@1 across DeepSWE, Terminal-Bench v2, and SWE-Atlas-QnA. Higher is better.
Let that sink in. Claude Code + Fable 5 (max, with fallback): 77. Codex + GPT-5.5 (xhigh): 76. One point. That's the gap between Anthropic's most powerful model at maximum compute and OpenAI's GPT-5.5 running at merely "extra high" reasoning effort.
But it gets better. Drop Fable down to max without fallback and it scores 73 — below Codex + GPT-5.5 at medium effort (71). Claude Code + Opus 4.8 at max? 73 — same as Fable, at half the price.
In other words: on the benchmark that actually matters, Fable 5 at full throttle barely edges out GPT-5.5 — and Claude Code + Opus 4.8 matches it entirely.
Now here's the cost comparison that should be on every slide deck in Silicon Valley:
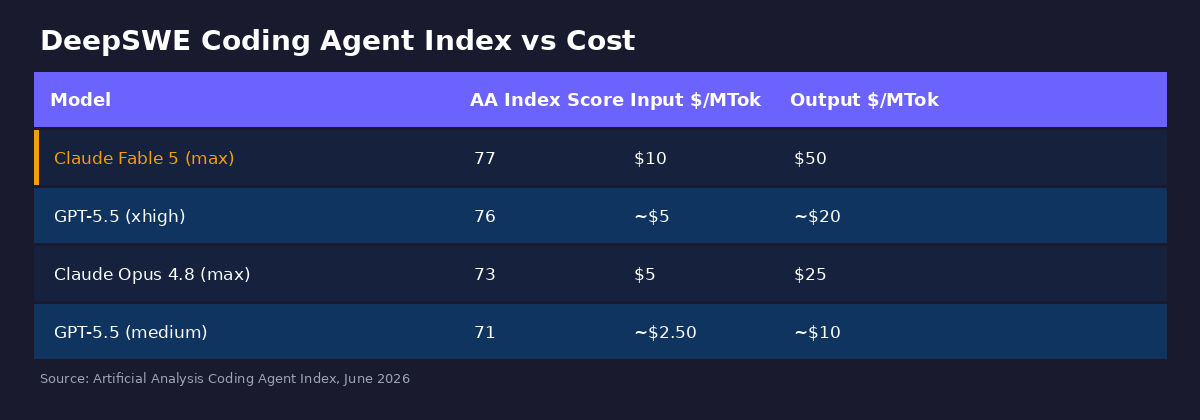
Fable 5 costs 2–5× more than GPT-5.5 depending on the effort tier you compare it to, for a 1-point lead on the gold-standard benchmark. One. Point.
And if you think the token pricing table above is abstract, here's what it looks like in cold hard dollars per task:
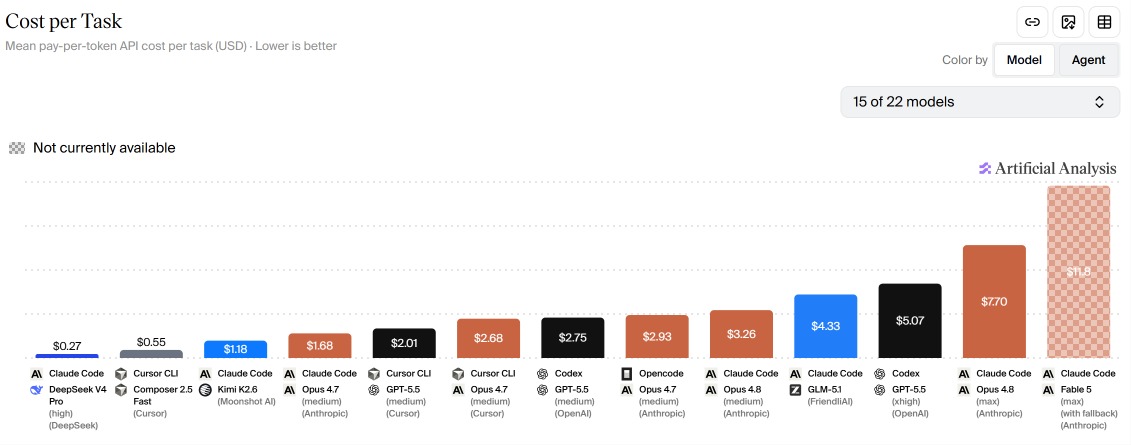 Source: Artificial Analysis Coding Agent Index — mean pay-per-token API cost per task (USD). Lower is better.
Source: Artificial Analysis Coding Agent Index — mean pay-per-token API cost per task (USD). Lower is better.
Claude Code + Fable 5 (max, with fallback): $11.50 per task. Codex + GPT-5.5 (xhigh): $5.07. Claude Code + Opus 4.8 (max): $7.70. DeepSeek V4 Pro at high effort: $0.27.
Fable 5 is literally 43× more expensive per task than DeepSeek, and 2.3× more expensive than GPT-5.5, for one benchmark point of advantage. If that's not a tax on brand loyalty, I don't know what is.
The V8 Problem: More Cylinders Isn't Engineering
There's a reason the automotive world moved on from the 6.2-litre naturally aspirated V8 as a performance benchmark. Yes, you can make anything fast if you throw enough displacement at it. But a turbocharged four-pot that extracts the same power while using half the fuel? That's engineering. That's elegance.
What Anthropic appears to have done with Fable 5 is the AI equivalent of boring out a V8 and calling it a revolution. The model — widely speculated to be architecturally identical to Opus 4.8 with inference compute roughly doubled — delivers meaningfully better results on long-horizon tasks. But at double the inference time and double the cost.
The Artificial Analysis Coding Agent Index makes it brutally clear: Claude Code + Opus 4.8 at max scores 73 on the composite DeepSWE/Terminal-Bench index. Fable 5 at max scores 73 too — identical — at double the price. The only time Fable pulls ahead is with the fallback safety net enabled, where it scrapes to 77 vs GPT-5.5's 76. One point. At 2–5× the cost depending on how you compare.
A Chevy Camaro ZL1 will beat a hybrid on a drag strip too. That doesn't mean it's a better car.
The truly elegant result would be: same compute, meaningfully better output. What Fable delivers is: better output, proportionally more compute. That's not a breakthrough. That's a dial turned up.
Act III: The Government Kills the Party (Three Days Later)
This is where the story tips from mildly embarrassing to genuinely extraordinary.
Three days after the triumphant launch of Fable 5 and Mythos 5, Anthropic was forced to publish this statement:
"The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees."
Let that sink in. Foreign national Anthropic employees couldn't use the model they'd just launched. Every API customer outside the United States — gone. All of them, including the UK, Europe, Asia — cut off within 72 hours of launch.
Anthropic's response was admirably defiant. They pointed out, correctly, that the "jailbreak" the government had been shown was essentially asking the model to read a codebase and fix security flaws — the kind of thing developers do every day. They noted that GPT-5.5 can do the same thing. They argued the safeguards were working.
None of this changed the outcome. The model that was supposed to be available to "as many users as possible, as quickly as we can" was unavailable to most of the world's developers before the launch week was even over.
For a company that had spent months cultivating an air of frontier inevitability, this was a spectacular face-plant. You can't be the future of global AI infrastructure if a government directive can pull the plug on your flagship model because of a "verbal demonstration" of a known vulnerability class.
What Is Fable 5, Really?
Let's be direct about the hypothesis that's circulating in developer circles: Fable 5 is Opus 4.8 with the compute knob turned to max.
Anthropic's own launch post is illuminating: "For a small group of cyberdefenders and infrastructure providers, we're also launching Claude Mythos 5. It's the same underlying model as Fable 5, but with the safeguards lifted in some areas."
So Fable and Mythos are the same underlying model. And Mythos Preview — the earlier, "dangerous" version — scored 93.9% on SWE-bench Verified. Fable 5 scores 95.0%. One percentage point of separation.
Meanwhile, Opus 4.8 was quietly shipped on May 28th, two weeks before Fable's launch, at the same price as 4.7. It scores 88.6%.
The pricing structure tells a story:
- Opus 4.8: $5/$25 per MTok — scores 73 on the AA Index
- Fable 5: $10/$50 per MTok — scores 73 on the AA Index (or 77 with fallback)
- GPT-5.5 at xhigh: roughly $5/$20 — scores 76 on the AA Index
This is the engine theory made real. The improvement exists — barely, on the one benchmark worth trusting. But it's bought, not engineered. You're paying for GPU time, not for a fundamentally smarter architecture.
"Safety-Focused" and US Government-Exclusive
Here's the irony that doesn't get enough airtime.
Anthropic positions itself as the safety-first, humanity-first AI lab. The company that took the responsible road. The adults in the room. Dario Amodei writes op-eds about existential risk. The company's Constitutional AI approach is genuinely interesting work.
And yet their most powerful models — Mythos 5 in particular — are gated behind US government contracts through Project Glasswing, unavailable to non-US developers, restricted to "approved cyberdefenders and infrastructure providers."
If your safety philosophy ends at the US border, it's not really a safety philosophy. It's a defence contractor relationship.
The UK, Europe, and the rest of the world built their entire development workflows around Claude because Anthropic sold them on the idea of a safer, more aligned AI partner. Then the US government issued a directive and every foreign developer found out in real time exactly how much sovereignty they have over the tools they depend on: none.
The IPO Question
Let's end where this was probably always going.
Anthropic raised $7.3 billion at a $60 billion valuation in late 2024. Reports in early 2026 suggested IPO discussions were ongoing, with target valuations climbing past $100 billion.
Now look at the last six months through that lens:
- Mythos Preview: Launch wrapped in government mystique and apocalyptic security claims. Maximum attention.
- Fable 5 + Mythos 5: "State of the art on nearly all benchmarks." Benchmark screenshots everywhere. Massive press.
- US government restriction: Anthropic plays the heroic whistleblower, publishing a detailed defence of their work. More press.
- SWE-bench domination narrative: The leaderboard sweep of the top six positions — all Claude models — gets screenshotted and posted everywhere.
Is any of this bad? Not necessarily. Products need marketing. Milestones deserve celebration.
But when the model is architecturally suspect, the safety claims don't survive scrutiny, the benchmark lead evaporates when you normalise for compute cost, the flagship gets pulled by executive order before the launch confetti has settled, and the company's founder is giving speeches about AI existential risk while shipping dual-use models to government cyber units...
You have to ask the question: Is this a product strategy, or is it a roadshow?
Because if Anthropic is serious about being the safety-first AI lab for the world, it needs to do better than:
- Hype a model nobody can use
- Launch a compute-expensive increment as a breakthrough
- Lose access to half the world within three days
- Position the fallout as a principled stand
The scoreboard is impressive. The engineering is real. But the story Anthropic is selling — frontier safety, global accessibility, genuine breakthrough architecture — doesn't match the evidence.
Maybe that's fine if you're raising money. It's not fine if you're building the infrastructure the world runs on.
Benchmarks via Artificial Analysis Coding Agent Index (DeepSWE / Terminal-Bench v2 / SWE-Atlas-QnA)
Related Posts
Frameworks vs Markdown: Why I Stopped Installing Agent Frameworks and Started Writing .md Files
There's a gold rush in AI-assisted development frameworks. I tried several, then built aibank using nothing but flat Markdown files and GitHub Copilot agents. Here's what I learned.
MCP Apps vs A2UI: Better Together
Vibe Coding Inception via WhatsApp
A story about AI building AI tools that build AI tools that build websites. Meta-circular development through six layers of abstraction, from WhatsApp messages to production deployments.